從擴展定律到世界模型,人工智慧模型演進的下一個商機
分析 AI 發展從「擴展時代」到「推理時代」再到「世界模型」的典範轉移。探討 Ilya Sutskever 的 100 小時學生理論、Karpathy 的認知核心概念,以及李飛飛、Google、LeCun 的三條世界模型路線,附投資機會分析。

自 ChatGPT 於 2022 年底問世以來,已經過去三年時間。
過去這段時間,全世界人工智慧模型主要的發展方向,可以說是一種.....暴力美學?
這種作法稱為擴展定律 (Scaling Law)。更多的參數、更多的 GPU 算力、更多的電力,就等於更強的智慧。
然而,這種思維在近期開始遇到了挑戰。最簡單的論點就是,如果我們的數據與電力走到了盡頭,這樣的模式還能夠繼續下去嗎?
所以,現在部分公司正從「訓練更大的模型」,轉向讓模型用更多時間「思考」。另外,則是從單純的語言模型納入多模態,並瞄準世界模型。
這場典範轉移不只會改變未來的技術路徑,更重塑了未來的投資邏輯。
第一階段:Scaling Law 的暴力美學與物理極限
在 2020 到 2025 年間,矽谷只有一個信條,那就是 Scaling Law(擴展定律)。
這是一個非常好懂的商業與技術公式:
「更多數據 + 更多算力 + 更多電力 = 更強的智慧」。
這條路徑之所以成為主流,是因為它清晰且有效。不管你是 OpenAI、Google 還是 Meta,只要有錢買到足夠的 NVIDIA GPU,蓋足夠大的資料中心,把整個網際網路的數據餵給模型,它的智商就會線性增長。這是一場單純的軍備競賽,大者恆大。
但到了 2025 年底,這個定律開始遇到阻礙。
最大的問題在於「數據耗盡」。高品質的網際網路數據基本上都已經被訓練過一輪了,剩下的都是重複或低質量的內容。再加上電力消耗已經讓全球電網不堪重負,例如,美國資料中心的建設速度就遠遠趕不上需求。
所以,盲目擴大規模(Scaling)的邊際效益正在急速遞減。這引發了產業內的一個關鍵問題:當數據與電力都走到盡頭,AI 該往哪裡走?
第二階段:重回研究時代,從「死記硬背」轉向「推理能力」
當暴力擴展失效,產業界爆發了一場關於「繼續擴展」與「轉向推理(Reasoning)」的路線之爭。這也是我們稱之為「重回研究時代」的關鍵轉折。
Ilya Sutskever:100 小時學生 vs 10,000 小時學生
OpenAI 聯合創始人、現任 SSI(Safe Superintelligence)創辦人 Ilya Sutskever 提出了一個非常傳神的比喻:
Q: 什麼是真正的智慧?
A: 想像有兩個學生準備考數學競賽。學生 A 練習了一萬小時,死記硬背所有題庫。學生 B 只練了一百小時,但他花時間理解公式背後的推導邏輯。
遇到沒見過的難題時,誰更有可能解出來?
Ilya 認為,應該是學生 B
但現在的 AI 更像是學生 A,雖然透過海量訓練數據獲得能力,但缺乏真正的理解與泛化能力。而我們需要的 AGI(通用人工智慧),必須是學生 B,因為他們才能從少量範例中領悟本質。
Andrej Karpathy:認知核心與「鋸齒狀智慧」
Tesla 前 AI 總監、OpenAI 創始成員 Andrej Karpathy 提出了幾個關鍵概念:
1. 鋸齒狀的智慧(Jagged Intelligence):現在的 AI 在某些領域強得可怕(如下棋、寫程式),卻會在基本邏輯或常識推理上犯下低級錯誤,最經典的應該就是「9.11 大於 9.9」這個數學題目。而這種不一致性是目前人工智慧模型的最大挑戰之一。
2. 認知核心(Cognitive Core):我們不需要模型背下整個網際網路(那是外掛資料庫的事),我們只需要訓練一個輕量、純粹的「推理引擎」。
3. 幽靈 vs 動物:我們並不是在模擬生物演化(像斑馬出生幾分鐘就能奔跑那樣的硬體能力)。我們只是在從網路上「召喚數位幽靈」,一種完全基於文字數據的精神實體。這意味著 AI 的智慧本質是一種模仿,它是人類思想與行為模式的數位倒影。這種差異決定了 AI 的能力與侷限。
新的競爭邏輯
所以,部分研究者認為,未來的人工智慧競爭,不再是比誰的模型參數大,而是比誰的「思考品質」高。這解決了數據耗盡的問題,因為我們不再需要餵給它更多的垃圾資訊,而是教它更好的思考方法。
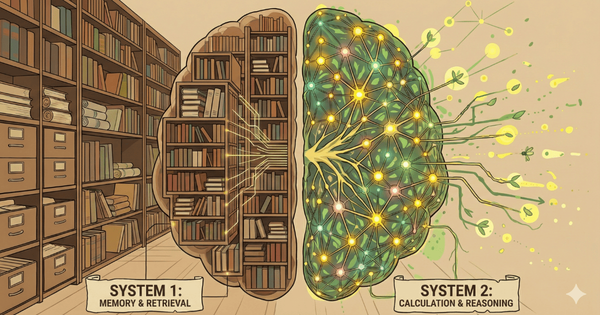
這種轉變催生了「推理時計算(Inference-time Compute)」的新範式:讓模型在回答前花 10 秒甚至更久進行內在推演,而非秒答。這就是從 System 1(直覺反應)到 System 2(邏輯推理)的轉變。
OpenAI 在 2024 年 9 月率先推出 o1-preview,首次將推理時計算帶入主流視野。而真正讓產業震撼的,是 2025 年 1 月中國 DeepSeek 推出的 DeepSeek R1。
DeepSeek R1 採用了「小模型 + 推理能力」的策略,總參數量為 671B(6710 億),但在推論時只採用 37B(370 億)參數。這種設計讓它在保持強大推理能力的同時,大幅降低了運算成本。
更重要的是,DeepSeek 證明了一件事:
你可能不需要無限大的模型,只需要一個會思考的模型。
第三階段:終極目標——世界模型(World Models)
除了從擴展理論到開始重視推理能力之外,現在的人工智慧模型也逐漸從個別的語言模型、生圖模型、音頻模型等,融合成多模態模型,並以「世界模型」作為目標。
方法論 vs 終極目標
「Scaling vs Reasoning」爭論的是「大腦該怎麼訓練與思考」(方法論),而「世界模型」是關於「大腦必須懂什麼」(終極目標)。
無論你訓練大腦的方法是靠堆積算力還是靠推理能力,AI 最終都必須通過「物理世界」的考試,才能真正成為 AGI。目前的語言模型只懂文字接龍,它知道「杯子掉在地上會碎」可能是因為訓練的文字資料裡有這樣的內容,而不是因為它知道重力與材質的物理交互作用。
三條通往真實世界的路
目前通往世界模型有三條主要路線,它們分別代表了不同的技術拼圖:
路線一:空間智慧(Spatial Intelligence)
代表:李飛飛的 World Labs(產品 Marble)
核心能力:從 2D 影片中重建高品質的 3D 場景,並且可以一鍵導出到 Unity 或 Unreal Engine。
價值:讓 AI 擁有「視覺」,看得見真實的物理結構。這是人機介面的關鍵,因為人類是視覺動物,需要高畫質的 3D 場景才能感覺「真實」。
批評:更像是「高級的 3D 掃描工具」,就像好萊塢的佈景,正面看很美,背面全是木架支撐。這是一條通往元宇宙的路,而非直接通往 AGI 的路。
路線二:互動模擬(Action & Consequence)
代表:Google 的 Genie 3
核心能力:模擬「如果我做動作 A,世界會變成 B」的因果關係,像是讓模型不斷地做白日夢,提供無限的、低成本的試錯環境。
價值:對於訓練通用代理非常重要,因為它提供了一個虛擬的物理實驗室。
限制:依然受限於「像素」。如果模型這一次「夢」錯了(比如夢見杯子掉下去沒有碎而是彈起來),機器人就會學到錯誤的物理知識。
路線三:抽象理解(Abstract Prediction)
代表:Meta 的 JEPA(Yann LeCun 主導)
核心能力:不預測下一個像素,而是預測物體的抽象特徵與狀態。比如看到一台車開過來,JEPA 不在乎車的顏色,只在乎它的速度向量和碰撞機率。
價值:這是通往 L5 自動駕駛和具身智能的必經之路。Tesla 的 FSD v12 基本上就是這類「視覺到決策」模型的大規模部署。
缺點:對人類很不友善,因為它是「黑盒子」,我們看不見它到底理解了什麼,只能通過它的行為來判斷。而且 Yann LeCun 也將離開 META。
終極整合
如果我們把這三條路線放在一起看,它們其實構成了一個金字塔結構:
- 底層:Marble 的完美外表,但不懂因果
- 中間:Genie 試圖連結,但精準度還不夠
- 頂層:JEPA 的完美邏輯,但沒有身體
真正的 AGI 需要 JEPA 的大腦來指揮,但需要 Marble 這種技術將抽象的物理交互渲染成人類可理解的畫面。或者反過來,用 Marble 生成的高精度數據來餵養 JEPA。
這場戰爭最終不會是三選一,而是看誰能先把這三者整合在一起。
投資典範轉移:從訓練到推論
這種技術典範的轉移,直接影響了資金流向。
關鍵轉變:訓練算力 → 推論算力
在 Scaling 時代,算力主要花在訓練那個巨大的模型上。訓練完後,用戶問問題,模型秒答(推論成本低)。
但在 Reasoning 時代,模型在回答前可能需要「思考」10 秒甚至更久(System 2 思維),進行大量的內在推演。這意味著推論階段的算力需求將指數級爆發。
投資機會地圖
硬體層:晶片與算力
- NVIDIA:依然是王者,但專注於高效能推論的 ASIC 晶片(如 Broadcom、Marvell 協助設計的 TPU/LPU)將迎來爆發。
- TSMC:真正的壟斷者,無論是 NVIDIA 的 GPU,還是 Google、Amazon 自研的 AI 晶片,全部都要找台積電代工。
平台層:完整技術堆棧
- Google DeepMind:擁有 Genie、Gemini、AlphaFold 的完整技術儲備。加上 YouTube 的無限影片訓練數據和 Waymo 的真實世界數據,在世界模型競賽中極具優勢。
數據層:物理世界數據
- Tesla:如果互聯網文字數據已經不值錢,那什麼最值錢?答案是「非公開的物理世界數據」。Optimus 與 FSD 每天都在收集真實世界的物理交互數據,這是其他公司難以複製的。
能源層:電力基礎建設
- 不論是 Scaling 還是 Reasoning,電力都是硬通貨。大量運算都取決於一個瓶頸:電力。
結論
過去三年,我們見證了太多次「領先者」的更迭。2022 年,所有人都以為 OpenAI 會一路領先。2023 年,Google 的 Gemini 和 Anthropic 的 Claude 證明了追趕者的爆發力。2025 年,中國的 DeepSeek 用更小的模型和更低的成本,挑戰了整個產業的假設,開源模型更是急起直追取得一定的市場份額。
這是因為 AI 的遊戲規則正在改變。當所有人都在比拼參數量時,推理能力成為新的分水嶺。當大家都在訓練語言模型時,多模態與世界模型開啟了新戰場。
每一次典範轉移,都將讓產業秩序重新洗牌。
現在的我們,可能正在逐漸脫離「只要砸錢就能讓模型變聰明」的簡單時代。
參考資料
媒體報導:
- Dwarkesh Patel (2025). "Ilya Sutskever – We're moving from the age of scaling to the age of research".
- Dwarkesh Patel (2025). "Andrej Karpathy — We’re summoning ghosts, not building animals".
產業動態:
- World Labs (2025). "Marble: A Multimodal World Model".
- Google DeepMind (2025). "Genie 3: A new frontier for world models".
- Meta AI Research (2025). "INTRODUCING V-JEPA 2,A self-supervised foundation world model".