記憶讓思考更有效率!DeepSeek Engram 論文可能重塑AI基礎架構
DeepSeek研究團隊發現,最佳AI架構應分配75-80%資源給計算、20-25%給記憶。這不只是技術優化,更揭示了一個產業變革的起點:當記憶可以從GPU卸載到CPU,整個AI基礎設施和應用生態將如何重組?

2026年1月,DeepSeek 和北京大學的研究團隊發表了一篇關於大型語言模型架構的論文,提出了一個核心創新:條件式記憶(Conditional Memory)。他們主張,語言建模包含兩種本質不同的任務——組合推理(需要動態計算)和知識檢索(本質是靜態查表),應該用不同的機制處理。實驗發現,在固定資源預算下,最佳配置是 75-80% 用於計算、20-25% 用於記憶。
這個發現的意義超越了工程優化。它揭示了兩件事:第一,記憶與思考的平衡可能存在某種普遍規律,認知科學的多個經典理論與這個比例驚人地吻合。第二,由於查表操作的「確定性」,記憶模組可以從昂貴的 GPU 預取到便宜的 CPU,效能損失不到 3%,這意味著 AI 的「知識容量」可以大幅擴展,而不受 GPU 記憶體限制。
這篇文章將會解讀 Engram 論文的核心創新,條件式記憶如何與條件式計算(MoE)互補,檢視認知科學如何驗證這個架構,並分析對 AI 產業的實際影響。
關鍵問題是:當「查表」與「計算」可以架構性地分離,整個硬體堆疊和應用生態會如何重組?
Engram 架構:條件式記憶與條件式計算的互補
讓我們先理解這篇論文在解決什麼問題。
論文指出,語言模型本質上包含兩種截然不同的任務:組合推理(compositional reasoning)和知識檢索(knowledge retrieval)。前者需要深度、動態的計算;後者處理的是局部、靜態、高度刻板化的模式,如專有名詞、固定搭配等。
現代 Transformer 的問題是:它缺乏原生的「知識查表」機制,被迫用神經網路去「計算」出那些本質上是靜態知識的內容。
想像一下:當模型要輸出「Diana, Princess of Wales」這個詞組時,它必須花費好幾層神經網路去「重新拼湊」這個組合。彷彿每次都要從頭推導出黛安娜是威爾斯王妃這件事。但這是一個固定搭配,全世界都這樣稱呼她,沒有任何需要「推理」的成分。論文的實驗顯示,解析這類常見的多 token 實體,會消耗多層早期的 attention 和 feed-forward 網路。
用一個比喻來說:這就像一個廚師,每次要用鹽的時候,都要從頭思考氯化鈉的分子結構、它如何與食材產生化學反應,然後才能動手撒鹽。顯然,對於「用鹽」這種高度固定的操作,直接從肌肉記憶中提取會高效得多。
條件式記憶:稀疏查表的新軸
Engram 論文提出的解決方案是:引入條件式記憶(Conditional Memory)作為與條件式計算(Conditional Computation,即 MoE)互補的稀疏性軸。
這個框架建立在一個對稱的設計上:
- 條件式計算(MoE):稀疏地啟用參數,來處理動態邏輯
- 條件式記憶(Engram):稀疏地查表操作,來檢索靜態知識
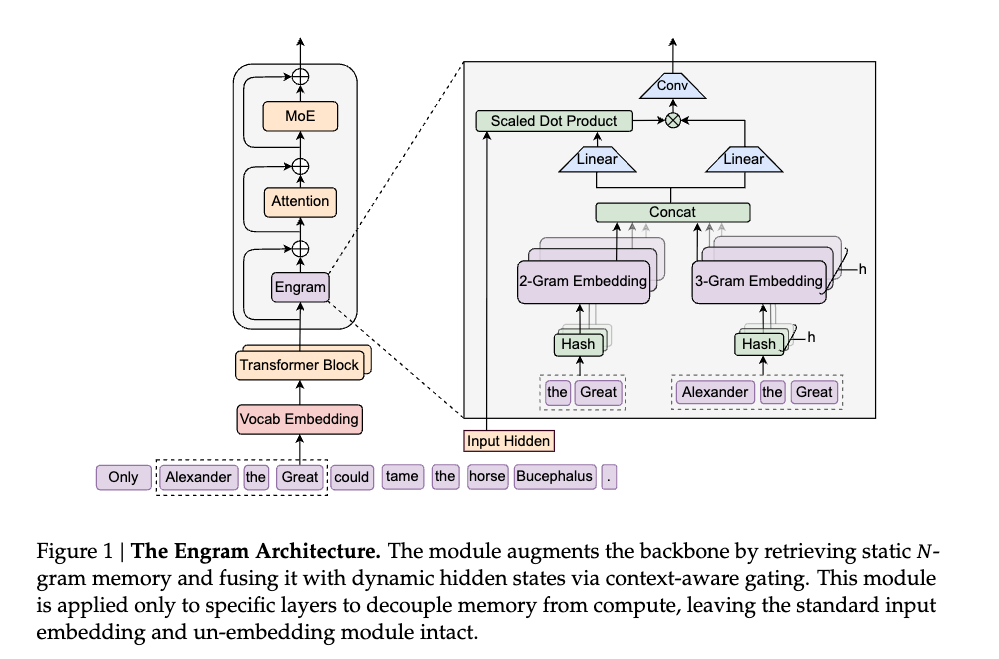
他們設計了一個名為「Engram」的模組(這個名字來自神經科學,指大腦中的「記憶痕跡」),用 N-gram 作為 key 進行 O(1) 查表。當模型遇到「Alexander the」,它可以用常數時間的查表操作,直接取出「Great」的組合;而不必動用昂貴的神經網路去「計算」接下來應該是什麼字。
關鍵問題是:在固定的資源預算下,應該分配多少給這種「記憶」,多少給「計算」?
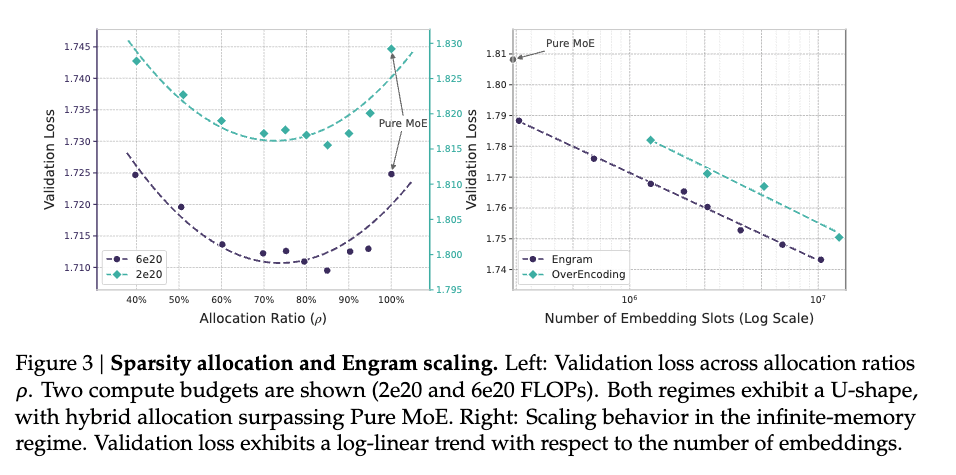
研究者做了大量實驗,發現了一條 U 型曲線。當把所有資源都給計算(沒有專門的記憶模組),模型表現不是最好的;當把太多資源給記憶,表現同樣下降。最佳配置出現在中間,大約 75-80% 給計算,20-25% 給記憶。
為什麼是U型曲線?
這個U型曲線揭示了一個重要洞察:條件式記憶與條件式計算不是互相替代的關係,而是互相支撐的關係。
太少記憶的問題:當把所有資源都給計算、沒有專門的記憶模組時,「模型缺乏存儲靜態模式的專用記憶,被迫透過深度和計算來低效率地重建它們。」每次都要從頭推導,是一種巨大的浪費。
太多記憶的問題:當把太多資源分配給記憶時,研究者發現「模型失去了條件式計算的能力,傷害了那些需要動態、脈絡相依推理的任務。」靜態查表無法取代動態推理。
令人驚訝的實驗結果
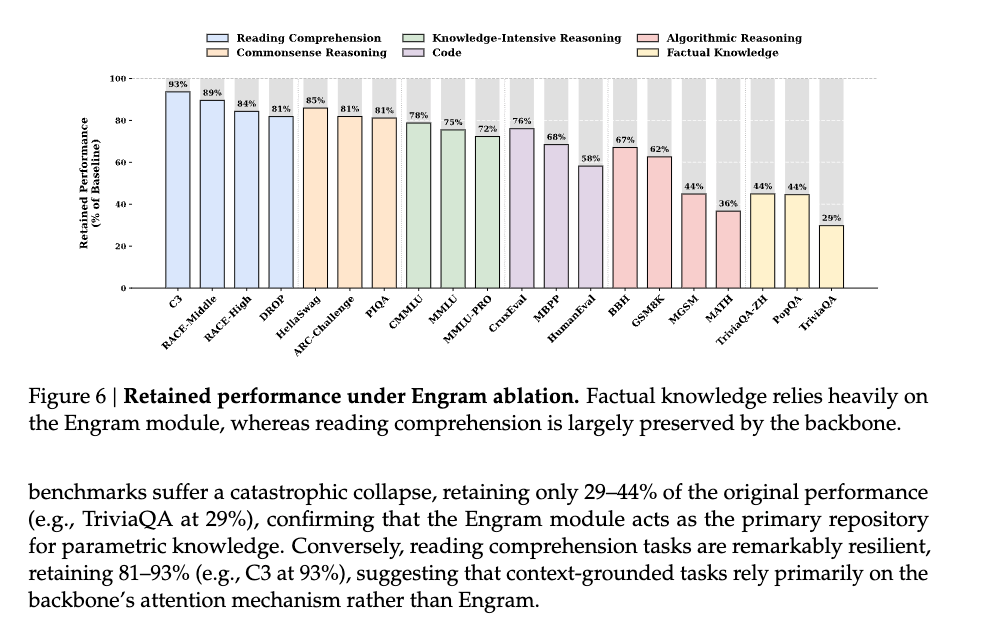
更有趣的是實驗數據揭示的模式。研究者將 Engram 與純 MoE 基準模型(嚴格控制參數量和FLOPs相同)比較,發現:
知識密集型任務(符合預期):
- MMLU: +3.4
- CMMLU: +4.0
- MMLU-Pro: +1.8
這些是本來就「應該」受益於記憶模組的任務,畢竟是在測試模型「知道」什麼。
但真正令人驚訝的是推理任務的提升更大:
一般推理:
- BBH(Big-Bench Hard): +5.0
- ARC-Challenge: +3.7
- DROP(閱讀理解): +3.3
數學與程式碼:
- HumanEval(程式碼生成): +3.0
- MATH: +2.4
- GSM8K(小學數學): +2.2
為什麼記憶模組對部分推理任務的幫助比知識任務還大?
論文的機制分析揭示:當模型不必花費早期的神經網路層去處理那些固定模式時,它就有更多「深度」可以用於真正複雜的思考。記憶模組釋放了模型的推理容量,讓它能夠把注意力集中在真正需要推理的部分。
這個發現暗示:好的記憶會讓思考更有效率。
認知科學如何驗證這個架構
Engram 論文的發現並非天外飛來的想法。它與認知科學的多個經典理論形成了驚人的對應。
康納曼的雙系統理論
最直接的對應是心理學家丹尼爾·康納曼的「雙系統理論」。在《快思慢想》一書中,他提出人類認知有兩套運作模式:
System 1:快速、自動、直覺。像是看到「2 + 2」直接知道答案,或是聽到「事實上」、「換句話說」這類詞組時,幾乎不需要任何思考就能處理。
System 2:緩慢、費力、邏輯。像是計算「17 × 24」需要一步步推導,或是面對複雜問題時需要深度思考。
Engram 的查表機制對應 System 1,神經網路的動態計算對應 System 2。論文的貢獻在於,它不只是概念上區分這兩種模式,而是在架構層面實現了它們的分離,並找到了最佳比例。
Miller 的組塊化理論
另一個對應是 George Miller 在 1956 年提出的「組塊化」理論。人類的工作記憶容量有限(著名的「7 ± 2」),但透過把資訊打包成「組塊」,可以大幅擴展有效容量。
西洋棋大師能在幾秒內記住整盤棋局,不是因為記憶力超群,而是因為他們把常見棋形視為單一單位——他們記住的是二十個「模式」,不是二十個獨立的棋子位置。或是我們一般在記憶電話號碼時,不會直接記住電話號碼「0912345678」,而是會分成「0912-345-678」這樣的組塊來記憶。
Engram 的 N-gram 存儲本質上就是組塊化的實現:「Alexander the Great」不是三個獨立的token,而是一個可以整體提取的單位。這解釋了為什麼論文的設計是「刻意節制」的,他們只存儲 2-gram 和 3-gram(兩到三個詞的組合),而不是所有可能的模式。實驗甚至發現,加入4-gram反而讓效果變差,因為稀釋了對更常用模式的容量。
McClelland的互補學習系統
還有一個更深層的對應:McClelland 等人在1995年提出的「互補學習系統」理論。他們主張大腦有兩套互補的學習系統:
海馬迴:負責快速記憶特定事件和事實。像是你昨天吃了什麼、見了誰,這些都存在海馬迴。
新皮質:負責慢速學習抽象模式和規律。像是「狗」這個概念、語言的語法規則,這些需要長時間累積才能形成。
這兩套系統必須分開運作,否則會互相干擾(所謂的「災難性遺忘」)。如果新皮質學習太快,會忘記之前學過的東西;如果海馬迴不夠快,就無法記住新的經驗。
Engram 論文的架構設計與此高度吻合:Engram 模組像海馬迴一樣存儲特定的知識組塊,Transformer 主幹像新皮質一樣處理需要泛化的推理任務。而且,正如生物大腦一樣,兩者的分離讓各自都能更好地發揮功能。
普遍規律的可能性
這些對應可能不是巧合。如果人類大腦經過數百萬年演化,發展出「記憶與計算分離」的架構,那麼這很可能是處理複雜資訊的高效解法。人工智慧模型的研究者透過實驗獨立「重新發現」這個架構,某種程度上是對認知科學理論的計算驗證。
有趣的是,認知心理學的研究也發現,人類在解決問題時,大約 70-80% 依賴推理和組合,20-30% 依賴直接提取的知識。這個比例與 Engram 的 75/25 驚人地接近,暗示:無論是生物智能還是人工智能,處理語言和知識可能存在某種「最優架構」。
產業影響:確定性查表如何重塑AI基礎設施
這篇論文還有一個容易被忽略、但對產業影響深遠的發現:Engram的查表操作是確定性的。也就是說,給定輸入序列,要查哪些記憶位置在計算開始前就知道。這個特性使得記憶模組可以從 GPU 預取到 CPU 記憶體,效能損失不到3%。
這個發現的意義,需要放在當前 AI 基礎設施的脈絡下理解。
確定性查表突破記憶體瓶頸
過去幾年,AI模型的規模爆炸式成長,但 GPU 的高頻寬記憶體(HBM)容量成長相對緩慢。一張頂級的 NVIDIA H100 只有 80GB HBM,而一個千億參數的模型光是載入權重就需要數百 GB。這造成了嚴重的瓶頸:不是算力不夠,而是「記憶體裝不下」。
Engram 的架構設計繞過了這個瓶頸。關鍵在於查表操作的確定性:
與 MoE 的動態路由不同,Engram 的查表是完全可預測的——給定「Alexander the」,系統在計算開始前就知道要查詢 ID 為 X 的記憶位置。這使得系統可以提前從較慢的 CPU 記憶體預取資料,與 GPU 計算重疊進行。論文實測:即使把一個 1000 億參數的 Engram 表完全放在 CPU 記憶體,推理速度也幾乎不受影響。
這意味著:模型的「知識容量」可以大幅擴展,而不需要等待更大的 GPU 記憶體問世。記憶體容量的限制從 GPU HBM 轉移到更便宜、更大容量的 CPU DRAM。
記憶體層級的新價值
如果這種架構成為主流,伺服器的設計邏輯將會改變。
傳統思維是「盡可能把所有東西放進 GPU」。新思維則是「分層存儲」:高頻存取的熱資料放 GPU HBM,中頻的放 CPU DRAM,長尾的冷資料甚至可以放 NVMe SSD。
論文特別指出,自然語言的 N-gram 遵循 Zipfian 分佈——少數高頻模式佔據大部分存取量——這讓快取策略特別有效。實務上,可能只有 5-10% 的記憶內容需要常駐 GPU,其餘 90-95% 可以放在更便宜、更大容量的記憶體層級。
這對硬體供應鏈的影響是:
可能受益的領域:
- 高容量、高頻寬的 DRAM(DDR5、LPDDR5X)
- 新一代記憶體互連技術(CXL,Compute Express Link)
- 企業級大容量 SSD
- 異質運算架構的系統整合能力
需要觀察的變化:
- 對頂級 GPU HBM 容量的極端依賴可能緩解
- 但這不必然是壞事,同樣的 GPU 可以服務更大的模型,市場可能反而擴大
- 伺服器架構從「GPU中心」走向「異質記憶體階層」
應用層的連鎖效應
硬體效率的提升,最終會傳導到應用層。
推理成本下降:如果大型模型可以更有效率地部署,API 定價可能進一步下探。這對所有AI應用開發者都是利多。更重要的是,這讓更多「邊際經濟效益不明顯」的應用場景變得可行。
邊緣部署的可能性:當「計算核心」和「知識庫」可以分離,一種新的部署模式變得可行,輕量的推理引擎在本地設備運行,大型知識庫按需從雲端串流。這對隱私敏感的應用(醫療、法律、金融)特別有吸引力。你的推理過程在本地,但可以存取雲端的專業知識庫。
知識的模組化更新:傳統上,要讓模型「學會」新知識,需要昂貴的微調或重新訓練。如果知識主要存在Engram模組中,理論上可以透過更新查表內容來「注入」新知識,而不動到核心推理引擎。這對企業級應用的維護成本有重大影響。想像一下:法律AI可以在法規更新後,只更新記憶模組,而不必重新訓練整個模型。
垂直領域的專業化:法律、醫療、金融等知識密集型領域,可以建立專屬的Engram表。共享同一個強大的推理引擎,但搭配不同的專業知識庫。這降低了垂直應用的開發門檻,你不需要從零訓練一個醫療AI,只需要建立一個醫療知識庫。
釋放注意力頻寬: 透過將局部模式(Local patterns)的重建交給 Engram,注意力機制不再需要浪費容量在這些瑣碎的關聯上,這讓模型在處理長文本(Long-context)時表現大幅提升。
投資與產業觀察
如果把視野拉遠,Engram 代表的是一種「AI基礎設施資本效率提升」的可能性。
打破競爭壁壘?
過去幾年,訓練和部署大型模型的成本曲線陡峭上升,形成了少數巨頭的競爭壁壘。如果記憶與計算的分離能有效降低部署成本、打破 GPU 記憶體瓶頸,AI 能力的「民主化」可能加速,更多公司能夠負擔得起部署強大模型,更多應用場景變得經濟可行。
但這也可能是雙面刃。降低門檻意味著競爭加劇,原本依賴「資本優勢」的公司可能面臨挑戰。相反地,那些擅長「垂直整合」和「應用創新」的公司可能受益。
值得關注的問題
對投資者而言,值得關注的不只是「誰在做 Engram」,而是更根本的問題:
-
硬體堆疊如何重組:當記憶可以從計算中解耦,誰會是新的受益者?是記憶體廠商、互連技術提供者,還是系統整合商?
-
應用生態如何演變:垂直領域專業化會不會成為主流?知識庫會不會像資料庫一樣,成為一個獨立的產業?
-
競爭格局如何變化:降低部署成本會讓競爭更激烈,還是會擴大市場讓所有人受益?
Engram 目前只是一篇論文,距離大規模商業部署還有時間。但問題不在於「會不會」,而在於「何時」。
當 GPU 記憶體瓶頸持續存在,當模型規模持續擴大,當推理成本成為商業化的關鍵,記憶與計算的分離不再是選項,而是必然。DeepSeek 用數據驗證了一個認知科學的觀點:記憶讓思考更有效率。這不只是 AI 架構的原則,也是所有智能系統的普遍規律。
對從業者而言,值得思考的是:在你的系統中,哪些部分該「記住」,哪些部分該「計算」?對投資者而言,值得關注的是:當記憶可以從計算中解耦,誰會在這場架構重組中獲益?
答案可能會在未來幾年逐漸清晰。但方向已經明確。
數據來源
學術論文:
- DeepSeek-AI & 北京大學 (2026), "Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models"
認知科學研究:
- Daniel Kahneman《快思慢想》
- George Miller (1956), "The Magical Number Seven, Plus or Minus Two"
- McClelland, J.L., McNaughton, B.L., & O'Reilly, R.C. (1995), "Why there are complementary learning systems in the hippocampus and neocortex"



