Google 讓 AI 自己畫出文字!這是走向 AGI 通用人工智慧的賭注!
當 Google 推出 NanoBanana Pro 時,一個奇怪的問題浮現:明明可以用現成字型庫保證 100% 正確,為何要讓 AI「自己畫」文字?這個看似多此一舉的選擇,藏著通往 AGI 的關鍵密碼。本文探討端對端生成的技術邏輯、Tesla 純視覺的相同策略,以及 AI 產業從訓練轉向推論的重大轉變。


Google 最近推出的 NanoBanana Pro 生圖應用在各大社群平台掀起熱議。這次最大的突破不只是畫得更美、更仔細,而是大幅改進了多語言文字生成能力,支援中文、日文、韓文等語言,文字渲染品質顯著提升。
但有個問題:明明可以用現成的字型庫(像 Photoshop 那樣貼上文字),保證 100% 拼寫正確,為什麼 Google 要用好幾個版本迭代,堅持讓 AI「自己畫」出文字?
答案藏在 Google 對 AGI 通用人工智慧的長期願景中。這個看似「多此一舉」的技術選擇,實際上是一場關於如何訓練人工智慧系統的重大賭注。這篇文章將深入探討 Google 與 Tesla 如何透過「移除輔助輪」來訓練 AGI,以及這對整個 AI 產業和 GPU 需求的深遠影響。
端對端生成 vs 工具調用:技術路線之爭
Google 的做法觸及了人工智慧領域一個核心的技術選擇題:端對端生成與工具調用的路線之爭。
簡單路:引用外部套件
就像在 Photoshop 裡貼上一個圖層。文字是完美的,拼寫 100% 正確,但它是「浮」在畫面上的。它不懂光影、不懂材質、不懂透視。
這種方法的優點顯而易見:
- 開發快速,技術成熟
- 文字永遠不會拼錯
- 可以使用現有的字型庫
但缺點也很明顯:文字與場景是分離的,無法產生真實的物理互動。
困難路:端對端自行生成
模型將文字視為「物體」的一部分,直接在像素層級生成:
- 如果畫面是霓虹燈,文字本身就是光源,會照亮周圍的牆壁
- 如果文字刻在石頭上,文字會有凹凸的陰影和風化的質感
- 如果文字寫在起霧的玻璃上,文字邊緣會有水氣的模糊感
這些物理互動是外部字型引擎無法自動計算的。
只有讓 AI 直接「畫」出文字,文字才能真正融入場景,產生照片級的真實感。
從圖片到影片:難度立方級提升
如果說在圖片裡生成文字是「畫家」,那在影片裡生成文字就是「導演 + 3D 特效師」。
這個難度呈現等比級數增加,想像以下這些情境:
- 遮擋關係(Occlusion):如果一個人走過帶有文字的牆壁,AI 知道人是「前景」,文字是「背景」,所以人會遮住文字,而不是文字浮在人的臉上
- 透視變形(Perspective):當鏡頭環繞著一個寫有字的杯子旋轉時,AI 會自動計算文字隨著圓柱體曲面轉動時的壓縮與拉伸
- 光影變化(Lighting):如果影片中太陽下山了,牆上的文字陰影必須跟著拉長,光線角度改變時反射也要相應調整
如果是用「外部套件」貼字,這需要極其複雜的 3D 建模和追蹤(Motion Tracking)才能做到,成本高昂且難以自動化。但現在的 AI 透過擴散模型(Diffusion Model)與 Transformer 的訓練,學習到這些物理互動的近似表現。
Google 的真正目標:訓練通往 AGI 的基礎能力
Google(以及部分 AI 業界頂尖實驗室)選擇這條路,反映了他們的長期目標:不想訓練一個「熟練使用 Photoshop 的操作員」,而是想訓練一個「擁有眼睛和手、真正理解物理世界的 AGI」。
什麼是 AGI?
AGI(Artificial General Intelligence,通用人工智慧)是一種假設的理論性 AI,目的是創造出能夠理解、學習並執行人類能夠執行的任何智力任務的機器。
與目前僅能執行特定任務的狹義 AI(Narrow AI)不同,AGI 應具備:
- 泛化能力:能將一個領域學到的知識應用到其他領域
- 常識推理:理解日常生活中的因果關係和物理法則
- 自主學習能力:能夠適應新情況並解決未曾被教導過的複雜問題
雖然 AGI 尚未實現,但業界預期它將具備過去人工智慧模型做不到的關鍵三大能力:
能力 1:從「概率模仿」到「因果推演」
目前的 AI:本質上是「高階鸚鵡」。它寫程式是因為看過類似的代碼;它畫香蕉是因為看過香蕉的圖片。它依賴的是相關性(Correlation)——看到 A 通常伴隨 B,所以當出現 A 時就輸出 B。
AGI 預期能做到的:它將擁有世界模型(World Model)。這意味著它能理解「物理定律」和「邏輯因果」,而不僅僅是統計關聯。
例子:
在開發新材料或藥物時,AGI 不需要把所有化學式都試一遍。它能像愛因斯坦進行「思想實驗」一樣,在腦中模擬:「如果我把這個分子結構改變一下,根據物理法則,它應該會變得不穩定,因為這會破壞電子軌道的平衡。」
在軟體開發中,它不是幫你寫一個 function,而是能幫你預判:「這個架構雖然現在能跑,但三個月後當用戶數達到 10 萬時,記憶體會因為這個模組的循環引用而崩潰。」這是基於邏輯推演,而非僅僅檢索 Stack Overflow 上的類似問題。
能力 2:從「單次任務」到「長程自主規劃」
目前的 AI:是「被動的」。你給一個指令,它給一個回應。對話結束,它的任務就結束了。它沒有持續的目標感或自主性。
AGI 預期能做到的:它將具備代理權(Agency)和長期記憶。
例子:
你可以給它一個模糊的、跨度長達數週的目標:「幫我開發一個類似 Uber 的 App,並部署到 AWS,這是我的信用卡,遇到 Bug 自己修,預算控制在 500 美金以內。」
AGI 會自己拆解任務:
- 分析需求 → 設計架構
- 寫代碼 → 跑測試
- 測試失敗 → 自己查 Log
- 自己修改代碼 → 重新部署
- 監控流量 → 優化性能
這中間可能經歷數萬次的自我迭代,它不會每遇到一個報錯就停下來問你「怎麼辦」。它會像一個真正的開發者一樣,持續工作直到任務完成。
能力 3:從「知識整合」到「新知識創造」
目前的 AI:生成的內容,本質上是人類現有知識的「重組」或「平均值」。它很難寫出超越人類現有水平的論文,因為它只能在訓練數據的範圍內插值。
AGI 預期能做到的:探索未知領域(Exploration)。
它可以在虛擬環境中進行數十億次的模擬演化,發現人類科學家從未發現的數學定理、物理材料或經濟學模型。這類似於 DeepMind 的 AlphaGo 發現了人類從未見過的圍棋策略。
例子:
針對總體經濟,現在的 AI 只能總結過去的歷史泡沫(如 2008 金融危機、1990 年代網路泡沫)。
AGI 可能透過模擬全球 80 億人的交易行為、心理偏誤、政策反應,發現一個全新的、反直覺的經濟週期理論,或者預測出下一次金融危機的具體連鎖反應路徑——而這個路徑在歷史上從未發生過,因此無法從訓練數據中學到。
為什麼「自行生成文字」是 Google 的起點?
回到我們最初的話題。Google 堅持讓 AI「自己學會寫字」而不是「調用字型庫」,正是為了訓練上述的第 1 點——因果與物理理解。
如果 AI 只能「調用工具」,它可能永遠只是個操作員。(但這也是一種有效的 AGI 路徑,業界對此有不同看法)
Google 的賭注是:只有當 AI 被迫去理解「筆畫是如何在三維空間中構成文字」的,它的大腦神經元才會建立起對空間、光影、邏輯的深刻理解。
而這些理解是可以遷移(Transfer)的:
- 今天它理解了文字的結構
- 明天它就能用同樣的邏輯去理解 DNA 的結構
- 或者晶片的電路結構
這種從一個領域到另一個領域的知識遷移能力,正是 AGI 的核心特徵。
Tesla 的純視覺策略:移除輔助輪訓練通用理解
說到這邊,或許有些朋友已經聯想到,Tesla 放棄雷達轉向純視覺,與 Google 的選擇是相同邏輯——為了獲得真正的「通用理解力」,必須移除「輔助輪」。
但這也是一種技術賭注,不代表其他路徑(如雷達 + 視覺融合)必然失敗。
第一性原理:模仿人類
Elon Musk 和前 AI 總監 Andrej Karpathy 的核心邏輯非常簡單且粗暴:
- 人類開車需要雷達嗎?不需要
- 人類開車需要雷射掃描嗎?不需要
- 人類依靠什麼開車?眼睛(視覺輸入)+ 大腦(神經網絡處理)
- 道路系統是為誰設計的?是為了生物視覺設計的(紅綠燈、標線、手勢)
如果 AGI 的目標是達到甚至超越人類的智力,那麼它必須能在「人類的感知維度」內解決問題。如果依賴雷達,它就不是在模擬人類智慧,而是在做一個特化的工業機器。
雷達的局限:缺乏語義理解
雷達 = 引用外部套件:
雷達能給你極其精確的「距離數據」。這很方便,程式設計師很容易寫出規則:「如果雷達偵測到前方 50 米有障礙物,煞車。」
問題:雷達沒有語義理解(Semantic Understanding)。它只知道那裡「有東西」,不知道那是「一塊石頭」還是「一個被風吹過的塑膠袋」。
這導致了著名的「幽靈煞車(Phantom Braking)」現象:雷達看到高架橋的陰影或金屬牌,以為是牆壁,強行煞車,造成後方追撞風險。
純視覺的挑戰與收益
純視覺 = 端對端生成:
這條路一開始很難。你需要訓練 AI 從 2D 的影片中,「腦補」出 3D 的深度和速度。這需要極強的推論算力和大量的訓練數據。
然而,一旦神經網絡學會了從像素中理解深度(就像人類一樣),它就:
- 不再需要昂貴的感測器(雷達、光達)
- 能理解語義:「那是塑膠袋,雖然雷達回波顯示有東西,但我知道可以直接撞過去沒關係。」
- 能處理邊緣案例:識別手勢、理解施工人員的指揮動作
強迫進化出「世界模型」
如果車上有雷達,神經網絡就會「偷懶」。它會依賴雷達提供的準確距離,而不會去努力學習「物體大小變化與距離的關係」或「遮擋關係」。
拔掉雷達,就像是把小孩丟進水裡學游泳。
Tesla 強迫 FSD 的神經網絡(v12 及後續版本採用 End-to-End 純視覺架構)必須僅憑影片就構建出完整的 3D 空間。這逼迫 AI 必須在內部建立一個高品質的 World Model(世界模型):
- 它必須理解物體恆存性(卡車擋住行人,行人沒有消失,只是被遮住了)
- 它必須預測物體軌跡(那輛車正在變換車道,我需要減速讓它)
這正是通往 AGI 的必經之路——從視覺輸入中理解物理法則。
為了 Optimus 機器人鋪路:通用智慧的遷移
Tesla 的野心不止於車。
如果你依賴雷達和高精地圖才能讓車子動起來,這套系統是無法移植的。你不能在人形機器人(Optimus)臉上裝一個旋轉的雷射雷達,也不能預先掃描你家廚房的 3D 地圖。
Tesla 的賭注是:如果我在車上解決了「純視覺通用導航」,我就可以把這顆「大腦」直接拔下來,安裝在 Optimus 機器人的頭裡。
因為不管是車還是人,導航的本質都是一樣的:
- 看見環境(視覺輸入)
- 理解環境(世界模型)
- 做出決策(行動規劃)
這就是 AGI 的定義:一套能應用於不同載體、不同任務的通用智慧系統。
從訓練算力到推論算力:AI 產業的重大轉變
這條「艱難但雄心」的路,正在改寫 AI 領域的基本定律——Scaling Law(縮放定律)。
舊的 Scaling Law 遇到瓶頸
過去幾年(GPT-3 到 GPT-4 的時代),Scaling Law 的信條是:「模型越大、訓練資料越多 = 越聰明」。
這就像是為了讓一個學生更聰明,我們拚命把更多的課本(數據)塞進他的腦袋,並讓他的大腦長得更大(參數)。
但現在遇到瓶頸了:
- 高品質的互聯網數據快被用光了:Common Crawl、Wikipedia、GitHub、Reddit 等公開數據源已經被反覆使用
- 訓練更巨大的模型,邊際效益在遞減:花 10 倍的錢,智商可能只提升 1-2%
- 電力供應出現問題:訓練 GPT-4 級別的模型需要數千顆 GPU 運行數月,能耗驚人
Scaling Law 的新維度:推論時縮放
「自行推理與思考」(如 OpenAI 的 o1 模型)為 Scaling Law 補充了新的維度:
這就像是告訴學生:「別再死背更多書了,考試時我讓你看書,給你 10 倍的作答時間,你好好想一想再寫。」
結果發現:一個中等大小的模型,如果讓它在回答前「思考(推論)」越久,它的表現就能超過一個「秒答」的超大模型。
這就是所謂的 Inference-time Scaling(推論時縮放)。
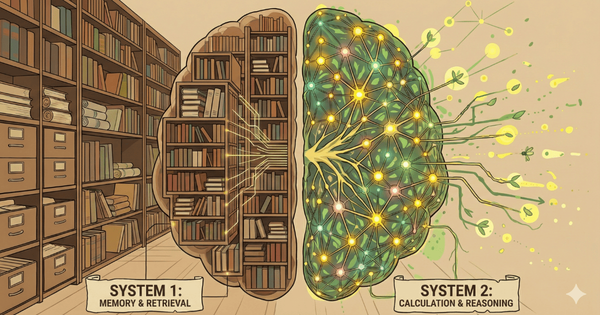
系統 1 與系統 2:快思慢想
諾貝爾獎得主丹尼爾·康納曼(Daniel Kahneman)在《快思慢想》(Thinking, Fast and Slow)中提出人類有兩種思維模式:
舊的 Scaling Law(System 1 - 快思):
- 直覺反應
- ChatGPT 秒回你,靠的是訓練時背下來的機率
- 這需要巨大的模型參數來涵蓋所有知識
新的方向(System 2 - 慢想):
- 邏輯推演
- 遇到難題(如寫程式、數學證明),模型會生成「隱藏的思維鏈(Chain of Thought)」
- 自我反思、試錯、修正,然後才給出答案
這意味著:我們可能不需要無限變大的模型參數(Parameters),但我們需要無限變多的推論算力(Compute)。不管你使用的是 Nvidia 的 GPU,還是 Google 的 TPU,還是 Apple 的 M1,都必須有足夠的推論算力來支持這種「慢想」的模式。
艱難但雄心的賭注
這也解釋了為什麼 Google 要走「自行生成文字」這種難的路——因為這是在鍛鍊模型的「大腦結構」(訓練算力),為了讓它將來在「思考時間」(推論算力)時,擁有正確的物理常識來進行推導。
如果基礎物理邏輯是錯的(靠外掛貼圖),給它再多時間思考,它也推導不出正確的影片物理效果。
同樣的,如果 Tesla 依賴雷達,神經網絡就永遠學不會真正的「視覺理解」,也就無法遷移到機器人或其他通用場景。
Google 選擇讓 AI「自己學會寫字」,Tesla 選擇讓 AI「自己學會看路」,不是為了炫技,而是在訓練一個「擁有眼睛和手、真正理解物理世界的智慧體」。
雖然現在這條路還很艱難(NanoBanana 生成的文字有時還是會飛走或拼錯,Tesla FSD 偶爾還會做出奇怪的決策),但 Google 和 Tesla 相信,一旦成功,它能呈現的智慧深度和創造力,將遠遠超過任何依賴工具的系統。
這條艱難的路,是 Google 與 Tesla 對 AGI 的雄心賭注。
重要提醒:端對端生成並非通往 AGI 的唯一路徑。業界也有聲音認為,混合方法(結合端對端學習與工具使用)可能是更務實的選擇。例如,OpenAI 的 o1 模型就整合了推理能力與工具調用。Google 的選擇反映了他們對品質、一致性和長期願景的優先考量,但不代表其他路徑必然失敗。
來源與延伸閱讀
- Google - NanoBanana Pro 官方介紹
- OpenAI - "Video generation models as world simulators" (Sora 技術報告)
- Google DeepMind - Veo 官方介紹
- Tesla AI Day - Andrej Karpathy 關於純視覺自駕的演講
- OpenAI - o1 系統卡片(推論時縮放)
- 相關研究 - Scaling Law 研究論文(Kaplan et al., 2020; Hoffmann et al., 2022)
- Daniel Kahneman - 《快思慢想》(Thinking, Fast and Slow)