2025 年人工智慧發展現狀:從對話走向推理
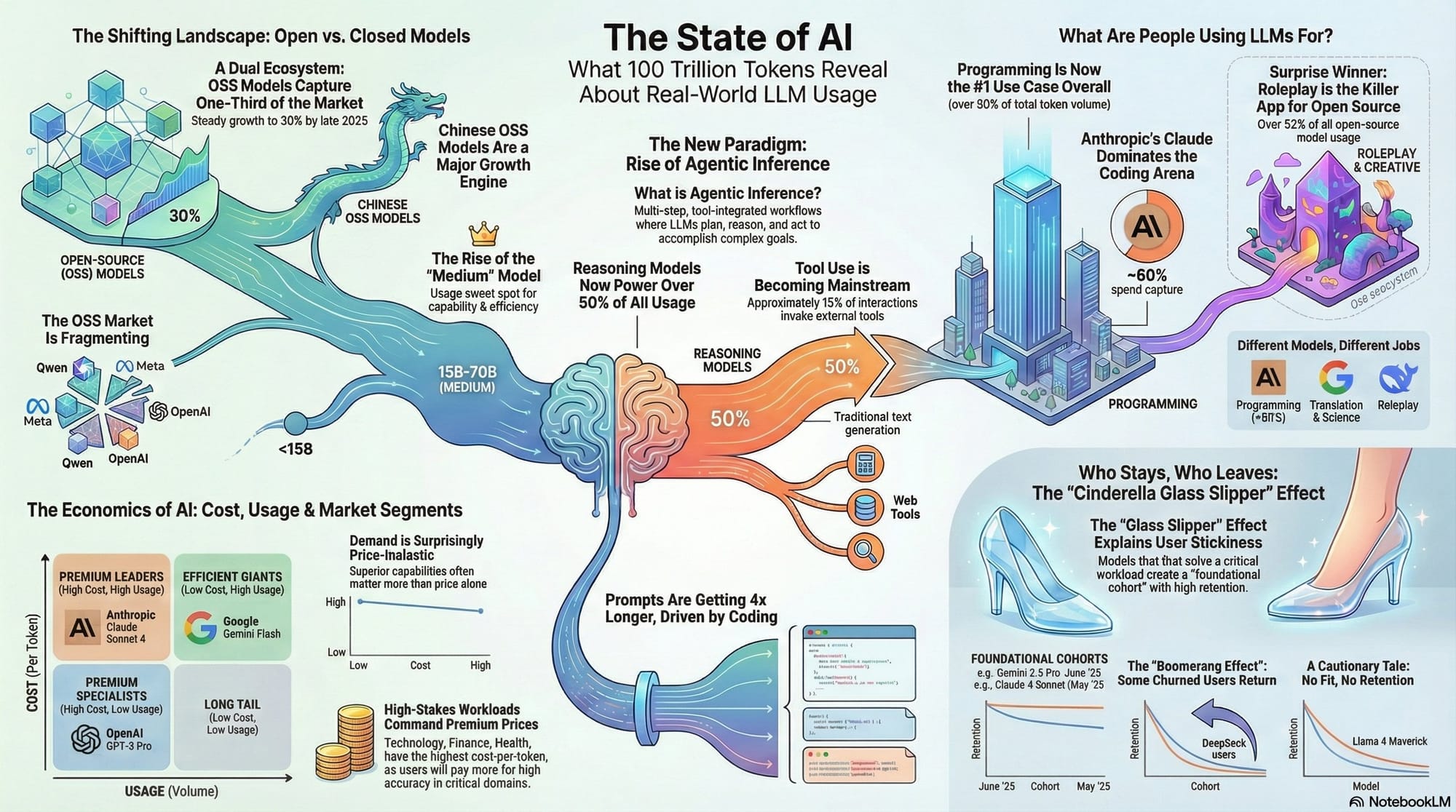
根據 OpenRouter × a16z 分析 100 兆 tokens 的「AI 現狀」研究,2026 年五大關鍵趨勢:代理推理取代單次生成、開源模型多元化、編程與角色扮演主導應用、灰姑娘效應決定留存率、價格彈性分化。AI 從「對話」走向「執行」。


OpenRouter 與 a16z 近期合作發布「AI 現狀」研究,分析超過 100 兆 tokens 的真實使用數據後發現:2026 年,AI 正式從「聊天機器人」進化為「自主代理」。超過 50% 的 token 採用推理優化模型,平均上下文長度從 1,500 暴增至 6,000 tokens,AI 已不再是回答問題的工具,而是能夠規劃、調用外部工具、自我修正的執行系統。
在這份基於百兆級真實數據的報告中,我挑出了五個關鍵趨勢:
- 代理推理的崛起:從單次生成轉向推理時計算,工具調用與長上下文成為標配
- 開源模型多元化:亞洲市場從 13% 躍升至 31%,中國模型(DeepSeek、Qwen)改寫競爭格局
- 應用場景兩極分化:編程(50%)與角色扮演(50%)主導,技術類任務溢價最高
- 灰姑娘玻璃鞋效應:早期精準解決用戶痛點的模型能長期鎖定用戶,後來者難以輕易撼動
- 價格彈性分化:高端市場質量壓倒價格,例如技術與科學領域用戶願付高溢價
接下來的內容會分析這五個關鍵趨勢,並推論 AI 產業未來走向。
代理推理的崛起:從模式匹配到深思熟慮
從單次生成到推論時計算的典範轉移
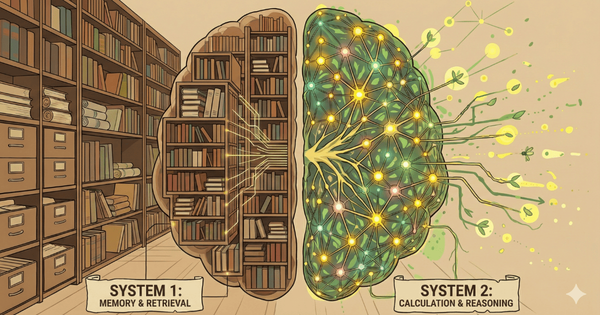
2024 年末至 2025 全年,AI 領域最大的變化,就是「生成答案」和「思考過程」的分離。在這之前,AI 就像是快速搶答的學生,看到問題就直接給出答案,但結果可能不符合用戶期待。
隨著 OpenAI 的 o1 與 DeepSeek R1 等推理優化模型的問世,引入了一種全新的運算範式,即模型在生成最終輸出之前,會先進行「推理時計算」(Inference-time Compute)。數據顯示,目前經推理優化的模型承載的 token 佔比已超過 50%,成為高價值任務的預設選項。
預計到 2026 年,這種「系統 2」思維將占據高價值算力週期的絕大多數。推理不再是一項商品化的檢索任務,而是一種隨著問題複雜度擴展的計算工作負載。我認為這種轉變將可能把定價模型從「生成的 token」轉變為「消耗的運算秒數」或「成功的任務結果」。
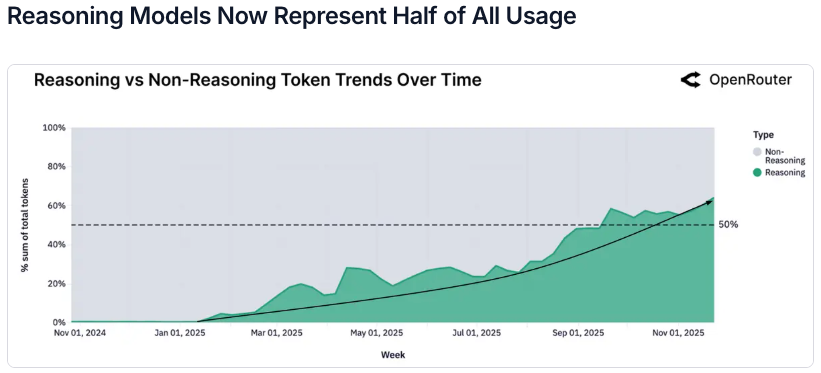
代理工作流的解剖學:上下文與工具的爆發
代理推理的特徵在於模型能夠作為更大自動化系統中的一個組件,而非獨立的對話者。這體現在兩個關鍵指標的激增上:
工具調用(Tool Use):成功調用工具的請求佔比全年顯著上升,模型不再僅依賴內部知識,而是主動操作外部 API。
上下文長度(Context Length):平均 Prompt 長度翻了四倍,從約 1,500 tokens 增至超過 6,000 tokens。平均序列長度(輸入+輸出)也從 2023 年末的不足 2,000 tokens 增長至 2025 年末的超過 5,400 tokens。
這一增長的主要推手是編程任務,其輸入長度通常是通用任務的 3-4 倍。這表明開發者不再只是詢問代碼片段,而是將整個文件甚至項目上下文提供給 AI 進行調試和重構,AI 已深度嵌入開發環境中。
推理模式的演變 (2024–2026)
| 特徵 | 單次生成時代 (2023-2024) | 代理推理時代 (2025-2026) |
|---|---|---|
| 主要互動模式 | 聊天 / 問答 | 多步驟工作流執行 |
| 上下文使用 | 低(僅對話歷史) | 高(RAG、代碼庫、工具定義 - 平均 Prompt > 6K tokens) |
| 推理機制 | 自回歸 Token 生成 | 思維鏈(CoT)/ 蒙地卡羅搜索 |
| 主導完成原因 | stop_sequence | tool_call / function_call |
| 價值指標 | 延遲(Latency)& 流暢度 | 成功率(Success Rate)& 推理深度 |
規劃能力的商品化與傑文斯悖論
隨著推理能力擴散到開放權重模型中,「規劃」(Planning)能力正在迅速商品化。在代理轉型的早期階段,只有前沿的專有模型能夠可靠地處理多步驟邏輯。然而,隨著 DeepSeek R1、Qwen 2.5 以及 Llama 4 等模型的崛起,代理能力的獲取門檻已被打破。
這種商品化創造了顯著的**傑文斯悖論(Jevons Paradox)**:隨著模型變得更便宜、更快,總 Token 消耗量反而爆發式增長。因為成本降低,開發者不再吝嗇 Token,開始構建更複雜的 Agent 循環和更高頻的自動化任務,低價正在解鎖全新的應用場景,而非單純導致市場萎縮。
市場動態:開源的多元化與地緣格局重塑
雙重割裂的市場:高智商 vs. 高通量
AI 市場並未同質化,而是形成了清晰的分工。成本與使用量的分佈揭示了兩個截然不同的世界:
閉源模型(高價值):OpenAI 和 Anthropic 占據「高成本、高價值」區域。用戶願意為複雜的推理、極致的可靠性和安全性支付溢價。
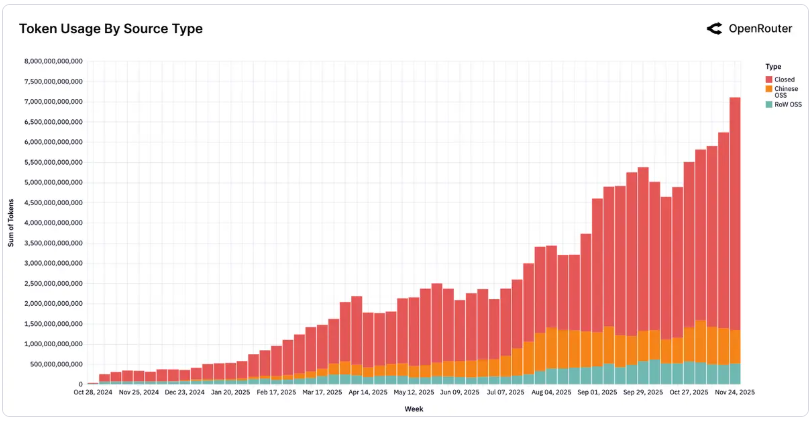
開源模型(大流量):DeepSeek 和 Qwen 等模型主導了「低成本、大流量」區域。到 2025 年末,約三分之一的使用量來自開源模型(OSS)。
值得注意的是,開源市場已從單一霸權走向多元競爭。至 2025 年末,無單一模型長期超過 25% 的開源市佔率,市場占比均衡分佈在 5–7 個主要模型之間。這意味著開發者不再默認選擇某一個「最佳」開源模型,而是根據具體任務在多個高性能模型間切換。
「中型」即是新的「小型」
模型尺寸正在經歷一場「中產階級勝利」。市場正在拋棄參數量小於 15B 的「小模型」,轉而擁抱 15B-70B 的「中型模型」(如 Qwen 2.5 32B, Llama 3.3 70B)。這一區間成為了兼顧能力與效率的黃金區間,提供了足夠解決複雜問題的智力,同時保持推理成本可控,實現了最佳的「模型-市場匹配」。
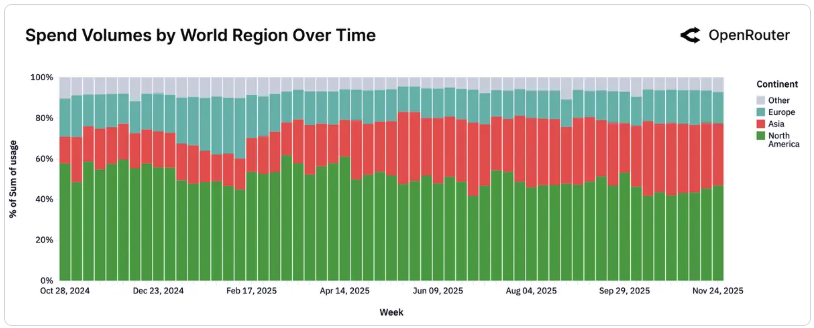
亞洲與中國模型的崛起
2025 年是地緣技術格局重塑的一年。亞洲市場的市佔率從約 13% 上升至約 31%,顯示出該地區在 AI 採用上的爆發力。其中,中國的開源模型(DeepSeek, Qwen)表現尤為搶眼,其週占比從 2024 年底 1.2% 一路攀升至 2025 年部分周次的近 30%,全年週均約 13.0%。
這不僅是數量的勝利,更是迭代速度的勝利。DeepSeek V3 和 Qwen 的快速發布節奏重塑了生態,特別是在編程和多語言任務上,它們已成為全球開發者的首選之一。
2025 年國家/地區使用量 Top 10:
- 美國(47.17%)
- 新加坡(9.21%)- 顯著高於預期,顯示其作為亞洲 AI 樞紐的地位
- 德國(7.51%)
- 中國(6.01%)
- 韓國(2.88%)
- 荷蘭(2.65%)
- 英國(2.52%)
- 加拿大(1.90%)
- 日本(1.77%)
- 印度(1.62%)
語言分佈:英語佔絕對主導(82.87%),其次是簡體中文(4.95%)。
領域特定轉型:編程與角色扮演的主導
兩大殺手級應用
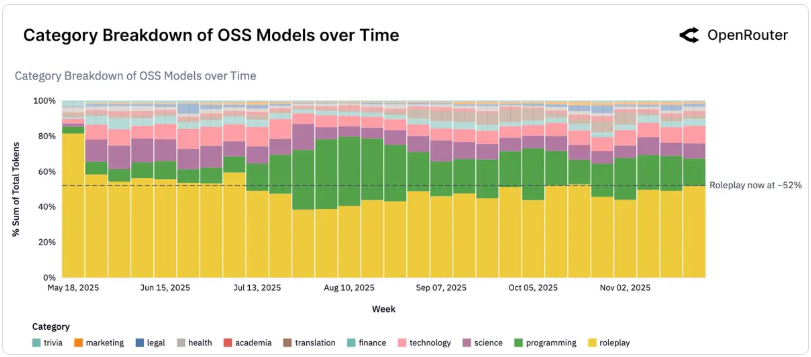
數據無情地揭示了 AI 使用場景的高度集中化。除了那些宏大的商業敘事,真實世界中 AI 最大的兩個用途非常樸素:
編程(Programming):這是增長最快速的類別,從 2025 年初的 11% 攀升至近期的 50%。它是付費/閉源模型的主要用途,也是推動 Prompt 長度增長的主因。
角色扮演(Roleplay):在開源模型的使用中,角色扮演占了超過 50% 的比例(在中國開源模型中約占 33%)。用戶在這裡尋求的是情感投射、不受限的創造力以及陪伴。
這兩個場景加在一起,構成了 AI 應用的半壁江山,遠超翻譯、法律或金融等領域。
不同提供商的應用分化
儘管編程和角色扮演主導整體市場,但各大模型提供商呈現出截然不同的用途分布,反映了各自的定位與用戶群特徵。
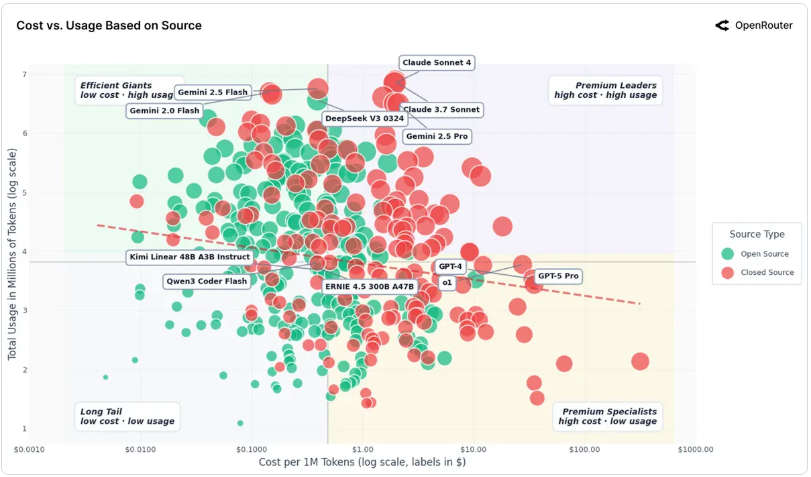
Anthropic:極致的技術專注
Claude 模型主要專注於編程和技術應用,這兩項合計佔其總使用量的 80% 以上。角色扮演和一般問答僅佔一小部分。這印證了 Claude 的定位:一款專為複雜推理、編碼和結構化任務而優化的模型。開發者和企業將 Claude 主要用作編碼助手和問題解決工具。
Google:最廣泛的通用覆蓋
Gemini 模型的使用範圍最為廣泛,涵蓋翻譯、科學、技術和通用知識等多個領域。約 5% 的應用涉及法律或政策內容,另有約 10% 與科學相關。與其他提供商相比,Google 的編程占比相對較小,且到 2025 年底進一步下降至約 18%。這表明 Gemini 正越來越多地被用作通用資訊引擎,而非專業開發工具。
xAI:從開發者到消費者的轉型
xAI 呈現出最戲劇性的變化。大部分時間裡,其使用量幾乎完全集中在編程領域(超過 80%)。直到 11 月下旬,其分布才開始擴大,在技術、角色扮演和學術領域均取得顯著成長。這種急劇轉變與 xAI 的模型透過特定消費者應用免費分發的時間點相吻合,引入了大量非開發者流量,形成了開發者核心用戶與通用用戶的混合使用模式。
OpenAI:從科學到編程的戰略轉移
OpenAI 的使用模式在 2025 年發生了顯著變化。年初,科學任務佔所有 tokens 的一半以上;到年底,這一比例已下降至 15% 以下。同時,編程和技術相關使用量現在佔總量的一半以上(各佔 29%)。這反映出 OpenAI 與開發者工作流程、生產力工具和專業應用的整合度越來越高,使用構成介於 Anthropic 的高度集中和 Google 的廣泛分散之間。
DeepSeek:消費者導向的角色扮演王者
DeepSeek 的用途分布與其他模型截然不同。角色扮演、休閒聊天和娛樂互動通常佔其總使用量的三分之二以上,只有一小部分活動屬於結構化任務。這種模式反映了 DeepSeek 強烈的消費者導向及其作為高參與度對話模式的定位。值得注意的是,DeepSeek 在夏末的編程相關使用量呈現小幅但穩定的成長。
Qwen:波動中的技術焦點
Qwen 的情況幾乎是 DeepSeek 的反面。編程類 tokens 始終佔所有 tokens 的 40% 到 60%,顯示其明顯側重技術和開發者任務。與 Anthropic 更為穩定的組成相比,Qwen 在科學、技術和角色扮演等類別中表現出更高的波動性。9 月和 10 月角色扮演使用量顯著上升,隨後在 11 月回落,暗示著用戶行為變化或下游應用路由調整。
應用場景的四象限經濟學:從大眾到專業的市場分割
四象限框架:成本與使用量的市場地圖
OpenRouter 的數據揭示了 AI 應用場景的清晰分割。透過將總使用量(Total Tokens)與單位成本(每百萬 tokens 成本)繪製成散點圖,可以觀察到一個關鍵現象:兩個座標軸都是對數尺度。這意味著圖表上的小距離,代表現實世界中倍數級的差異。
市場以中位數成本 $0.73/百萬 tokens 為界,形成了四象限框架:
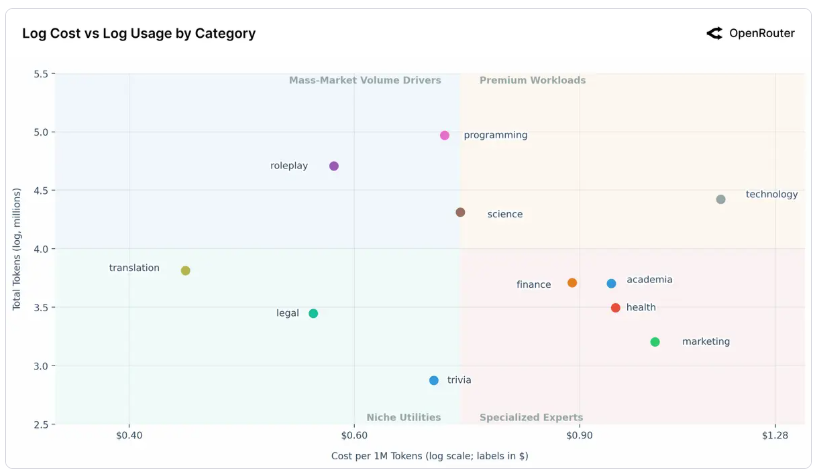
象限一:高價專業工作負載(右上角)
特徵:高成本 + 高使用量
這個象限代表最有價值且使用頻繁的專業場景。用戶願意為性能或專業能力支付溢價。技術(Technology)和科學(Science)應用位於這個區域的交界處。
「技術」類別:最大的離群點
在成本與使用量的分佈圖上,「技術」類別是一個巨大的離群點。它不僅使用量巨大,而且單位 Token 成本遠超其他所有類別,是圖表中最昂貴的應用場景。
這說明在涉及系統架構、複雜技術方案解決等領域,用戶對質量要求極高,對價格不敏感。這是屬於高端閉源模型(如 Claude 3.7 Sonnet、GPT-5 Pro)最穩固的盈利陣地,用戶心甘情願為「硬核知識」支付數倍的高昂費用。
關鍵問題:這個高價是由「需求端」驅動(用戶價值高,願意付費),還是「供給端」驅動(服務成本高,需要最強大的前沿模型)?無論答案為何,這都代表了一個高利潤率的市場機會。
象限二:大眾市場流量引擎(左上角)
特徵:高使用量 + 低成本(等於或低於中位數)
這個象限由兩大殺手級應用主導:
編程(Programming):「專業殺手級應用」的代表,展現最高的使用量,同時成本高度優化,維持在中位數水平。這證明了編程是 AI 最主要的專業生產力工具。
角色扮演(Roleplay):使用量幾乎與編程匹敵,這是一個驚人的洞察——消費者導向的角色扮演應用,驅動的參與量與頂級專業應用相當。
這兩個類別的規模確認了 AI 的兩大核心驅動力:專業生產力與對話娛樂。這個象限的成本敏感性正是開源模型找到顯著優勢的地方。
象限三:專業專家服務(右下角)
特徵:低使用量 + 高成本
這個象限包含高風險、小眾的專業領域,如金融(Finance)、學術(Academia)、健康(Health)和行銷(Marketing)。
較低的總使用量是合理的——人們諮詢 AI 進行「健康」或「金融」建議的頻率,遠低於「編程」。但用戶願意為這些任務支付顯著溢價,因為對準確性、可靠性和領域特定知識的需求極高。
象限四:小眾實用工具(左下角)
特徵:低成本 + 低使用量
這個象限包含功能性、成本優化的實用工具,如翻譯(Translation)、法律(Legal)和常識問答(Trivia)。
翻譯在這個群組中使用量最高,常識問答最低。它們的低成本和相對低使用量暗示這些任務可能已被高度優化、「解決」或商品化,存在便宜且足夠好的替代方案。
經濟學總結:價格彈性與商品化
四象限分佈揭示了一個關鍵的經濟學洞察:高端市場的價格彈性極低。
儘管存在傑文斯悖論(降價導致總量上升),但在涉及複雜任務(象限一與象限三)時,質量、可靠性和集成度顯著壓倒價格。用戶不會單純因為便宜就切換模型,除非新模型能解決他們的核心問題。這意味著市場尚未完全商品化,高端模型仍擁有強大的定價權,而低端任務則快速走向價格戰。
「灰姑娘玻璃鞋效應」:留存率的生死線
報告確認了一個極具洞察力的概念:「灰姑娘玻璃鞋效應」(Cinderella Glass Slipper Effect)。這意味著一旦某個模型在發布初期完美適配了用戶未被滿足的特定痛點(即「穿上了玻璃鞋」),它就會形成極強的鎖定效應,後來者即便性能更強也難以撼動。
正反案例研究
正面案例:OpenAI GPT-4o Mini
該模型是「玻璃鞋效應」的典型代表。發布初期,它精準解決了一類特定工作流(高性價比、快速響應)的需求,成功鎖定了一個「基礎用戶群」,這些用戶的留存率表現出驚人的穩定性。
負面案例:Gemini 2.0 Flash
儘管性能強大,但 Gemini 2.0 Flash 在發布時未能建立這種「適配」,導致陷入低留存的泥潭。這證明了 AI 競爭不是線性的性能比拼,而是對「特定時間窗口」和「特定場景痛點」的搶占遊戲。
DeepSeek 的「迴力鏢效應」
留存率分析中還出現了一個反常的**「迴力鏢效應」(Boomerang Effect)**。不同於大多數模型留存率的單調下降,DeepSeek 的部分用戶群在流失一段時間後會出現「復活」回流。
這表明用戶在嘗試了市場上其他替代品後,發現 DeepSeek 在特定的技術性能或性價比上依然具有不可替代的優勢,最終選擇回歸。
結論
2026 年的 AI 版圖由「代理推理」的技術範式和「雙軌制」的市場結構共同定義。我們正從一個「對話」的時代走向「執行」的時代,AI 不再只是回答問題,而是在閱讀整座圖書館(長上下文)並自主調用工具來解決問題。
競爭的關鍵不再是單一的榜單分數,而是誰能利用「灰姑娘效應」率先搶佔高價值工作流。中國模型的崛起和亞洲市場的爆發證明了開源生態的活力,而編程與角色扮演的兩極分化則揭示了人類對 AI 最真實的需求:一是生產力的極致輔助,二是情感與創意的無限延伸。
對於企業而言,2026 年的戰略重點應是識別那些對價格不敏感的「技術」與「推理」場景,並利用代理 AI 重構核心業務流程。
定價範式轉移:隨著推理模型佔比過半,我認為定價將可能從「按 Token 計費」轉向「按計算單元」或「按任務結果」計費。
硬體赤字:推理需求的激增(特別是長上下文和多步驟推理)可能在 2026 年造成 AI 硬體赤字,推動對專用推理芯片的需求。
投資視角:從訓練到推理的資本遷徙
基於上述的「定價轉移」與「硬體赤字」,資本市場的熱點正在從單純的「訓練基礎設施」向「推理與應用層」遷徙。這為投資者指明了三個關鍵方向:
1. 推理晶片的專用化 (Inference ASICs)
隨著推理成本成為科技巨頭最大的支出項目,通用 GPU(如 NVIDIA H100/Blackwell)雖然仍是王者,但市場將更青睞能降低單位推理成本的解決方案。
- 客製化晶片設計者:如 Broadcom (AVGO) 和 Marvell (MRVL)。它們協助 Google (TPU)、AWS (Inferentia) 和 Meta (MTIA) 設計專用推理晶片,這類 ASIC 需求將隨著推理量暴增而成長。
- 邊緣運算 (Edge AI):為了降低雲端推理成本,部分推理將轉移至終端設備。Qualcomm (QCOM) 和 Apple (AAPL) 等具備強大 NPU 設計能力的公司將受惠於「混合 AI」架構。
2. 代理平台的護城河 (Agentic Platforms)
當定價轉向「按結果計費」,擁有企業工作流數據並能實際執行任務的平台將獲得最高溢價。
- 企業代理 OS:Salesforce (CRM)、ServiceNow (NOW) 和 Microsoft (MSFT)。這些公司不只是提供 AI 聊天機器人,而是將「代理」嵌入到銷售、客服和 IT 運維的標準流程中。它們最有能力捕捉「灰姑娘效應」,因為它們已經掌握了企業的核心工作流。
2026 年的投資邏輯,或許應從「誰在賣鏟子(訓練晶片)」,轉向「誰能用最便宜的成本挖礦(推理效率)」以及「誰擁有金礦的開採權(企業工作流入口)」。
數據來源
研究報告:
- OpenRouter & a16z (2025). "State of AI: An Empirical 100 Trillion Token Study with OpenRouter"
- Gartner AI 產業預測報告 (2025)
- Forrester AI 市場研究 (2025)
- McKinsey AI 應用趨勢報告 (2025)
技術數據:
- OpenAI o1 模型技術文檔
- DeepSeek R1 發布資訊
- OpenRouter 平台使用統計
產業報告:
- 賽迪研究院 AI 產業報告
- a16z AI 市場研究
- SignalFire 技術趨勢報告